
 选择城市
选择城市

| 2019年留学备考规划>>点 击查看 | ||||
| 托福 | 雅思 | GRE | GMAT | SAT |
12月SAT北美亚太成绩已经公布,惊人的算分表又一次让同学们黯然神伤。以下是根据同学们的成绩单信息,整理的算分表。感觉考得还不错,但是扣分极其严格,这可“肿么办”?
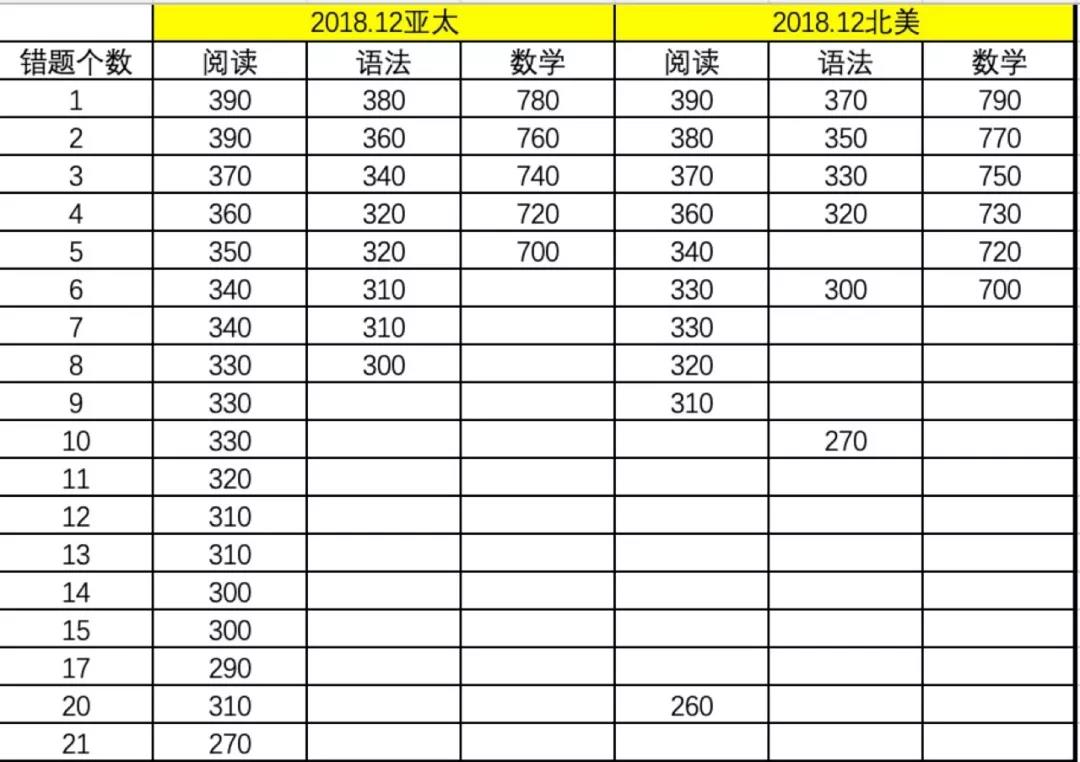
自6月份以来,SAT的算分表逐渐成为了家长和同学们关注的对象。大家现在不仅关注预计能对多少道题目,更越来越关注这套题目正确题目个数与分数之间的关系,也就是裸分和实际分之间的关系。
以往,这种关注度不高,主要原因是算分表相对稳定,最严格和最宽松的算分表差距也就是每科目10-20分的差距。
但自今年6月北美爆出语法错一个扣30,错两个扣50分,紧接着10月、11月两次北美算分表都十分严格后,大家再也无法平静。即使觉得这次考试很简单,也开始担心算分表会严格到让1500处不可及,也开始担心即使错题个数大幅减少,分数却变化不大。
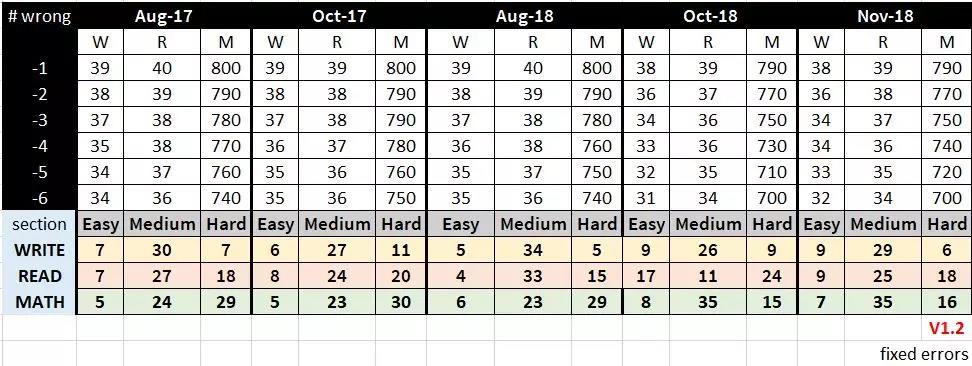
(以上为外国热心网友整理的2018年6月-11月高分区域算分表source:https://imgur.com/g2J0VKk)
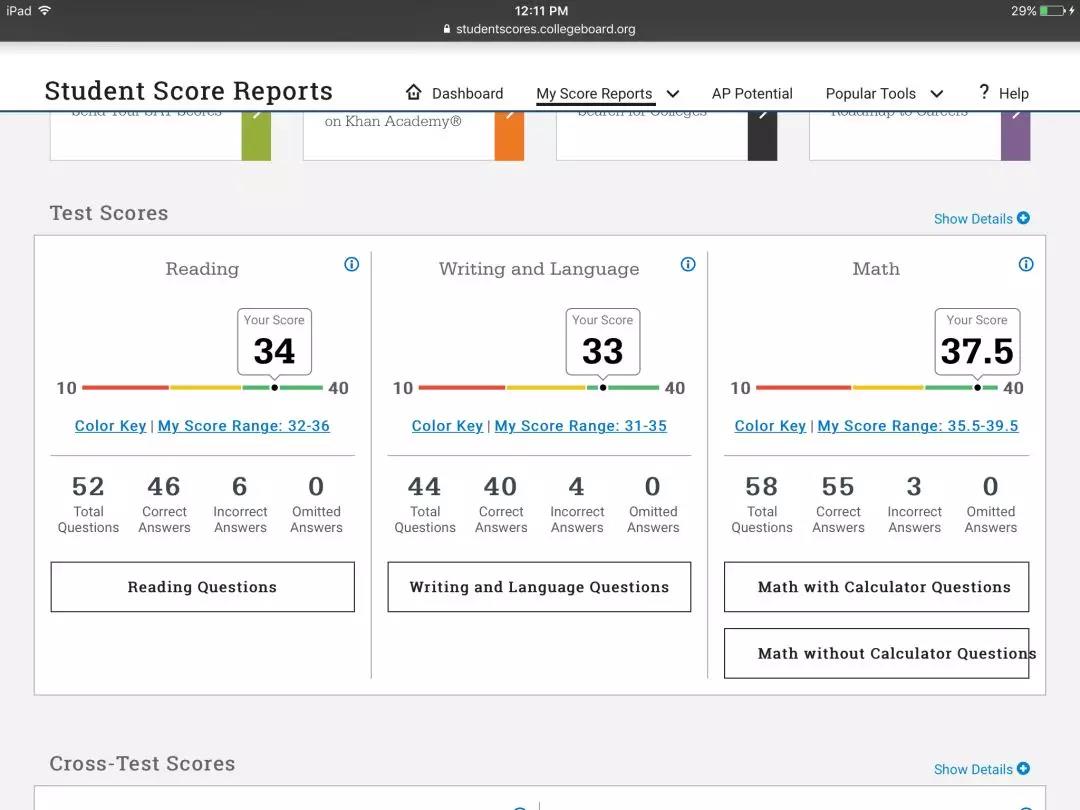
(上图为2018年6月某位同学的算分表,语法错4题扣除了70分)
新SAT的curve为什么会这样,老SAT为什么没有这样的问题呢?
本文试图通过ETS和CB公开的资料和数据,帮助读者探讨背后的可能成因,感兴趣的家长和同学们亦可阅读。
原始分(raw score)、报道分(scaled score)和分数转换(conversion)
原始分是出题人赋值给每道题目的原始分数。而报道分则是考试结束后,学生们收到的分数。比如我们大部分省市的高考就属于原始分和报道分相一致的考试,分就摆在你面前,你爱赚不赚,错多少扣多少。
但是有的时候,因为某些原因,原始分和报道分之间通常不一样,需要进行转化。比如笔者上大学的时候,一门很难的课程,老师为了怕大家的原始分数不及格,通常会根据大家的整体情况在分数登入教务系统前进行分数调整。
最经典的方式有:
1)所有学生加上100分与裸分第一名之差。这样第一名是100分,保证了“客观公正”,所有的学生分数都会整体平移,但是如果班里有一个非常厉害的人考了100分,那就灾难了,这就意味着大家的分数将不会变化。
2)所有学生分数开根号再乘10。这个算法相当于进行了一下分数平滑。整体学生分数都会上移,但是100分的学生计算之后还是100分,0分的学生计算之后还是0分。
我们把原始分变成报道分的过程称之为分数转化(conversion)。我们的教授进行分数转换的目的很明确,就是为了变相提高我们的成绩。
但是像SAT和TOEFL这种标化考试,要进行分数转化则不是为了给同学们一些unfair advantage。恰恰相反,是为了让考试公平。
标准化考试称之为标准化考试,不仅是因为它的操作流程是标准化的,而且也因为考试分数具有可比性。
举个例子,高考就是一个非标准化的考试。北京的670分和河北的680分不好比较哪个学生能力更强。而北京考生甚至自己本身也无法进行跨年比较,2017年的680分和2018年的670也无法比较。
但是TOEFL和SAT不同,只要成绩在有效期内,不同地点、不同场次、不同时间的考试都可以最终用分数进行比较,这就是分数转换的功劳。
那么SAT是如何进行不同场次考试的分数转换呢?这就要用到一个“神器“,conversion tables。每一套题目都有与其对应的唯一一个分数转换表。比如下图就是2018年5月份国际考试的分数转换表。
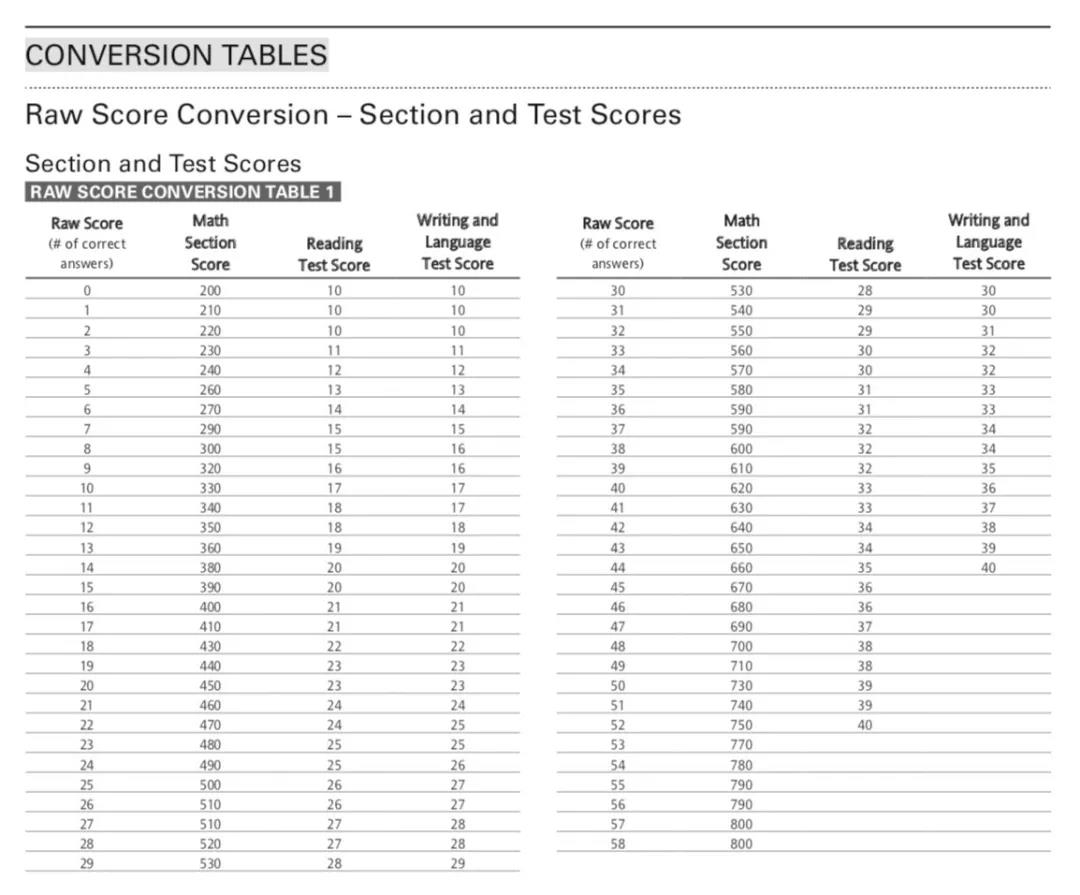
分数转换表是如何制定的?——从老SAT谈起
其实,大家最好奇地是CB,或者说ETS(SAT考试实际由ETS承担命题、批卷和算分的工作)是如何计算出每套题目的分数转换表的呢?具体的过程十分复杂,涉及到很多高端的科学知识,但是基本的原理却很容易懂。
我们假设全世界第一套SAT基准卷子称为form A,这套卷子须经过大量的测试,可以非常准确地测试出学生成绩,而且这套题目的算分表也已经成型。这就是为什么一个考试一开始开发的慢,但是越到后来速度会加快,因为最原始的考题和算分基础定好之后,将会直接影响未来后续的成绩情况,所以所有的测试会非常慎重。
我们只有一套form A是不够的。虽然理论上考完后题目应该不会泄漏,但是实际情况并非如此,而且对于美国时差跨越较大,很有可能会通过时差作弊。所以这个时候,研发人员要继续开发form B/C/D/E/F/G……(大家每次在考试的时候,会发现试题册背面有一个FormID,就是这套试题的代码)
那么问题来了,form B的raw score不可能直接用form A转换表进行分数转换,因为这两套题目的难度可能存在差异。如何确定form B的算分表呢?
一个非常笨的方法,就是在这套题目使用之前招募很多学生,让同学们同时做form B和form A。然后我们观察这一波人在这两套试卷的表现,从而获得对应关系。我们以语法section为例。如果我们大数据发现,做form B的同学一般语法错3个的,在做form A的时候基本错2个,那就说明form B语法错3个的得分应该和formA语法错2个的得分保持一致。
如果这个样本有足够的说服力,那么就可以用这个样本数据,测出所有form B的raw score和 formA的raw score的对应关系,进而形成了form B的算分表。
但是我们不可能在这套form使用之前招募太多的被试,不仅费钱,而且可能存在试题泄漏的风险。因此我们对于form B算分表的测试,要在考试的时候同步进行才可以。听起来好玄幻对吧,其实这就是老SAT获取算分表的方式,称之为external-anchor design。ETS公开的材料指出在老SAT中使用external-anchordesign操作的全过程。

(上图选自2016年笔者到ETS培训时,培训师的讲义材料,向我们揭示了ETS分析anchor items的大致方法)
An external anchor is a common measure, separate fromthe test itself, that we can use to compare the group of test takers taking thenew form with the group taking the reference form. Ideally, the external anchorshould measure the same knowledge and skills as the test to be equated, usingquestions or problems in the same format, administered under the sameconditions. In reality, we cannot oftencome close to this ideal. However, there is one well known test on which scoresare equated through an external anchor design that meets these idealconditions—the SAT Reasoning Test. Each form of the test includes a sectionthat is not the same for all test takers. There are several versions of thissection, spiraled among the test takers, so that the group of test takerstaking each version is a representative sample of the full group of test takersfor that administration. Some test takers get an additional Critical Readingsection; some get an additional Math section; some get an additional Writingsection. For some of the test takers, this section is an anchor that links thecurrent form to a previous form. For others, it is an anchor that will link thecurrent form to a future form. Because the anchor is not taken by all the testtakers, the scores on the anchor are not included in computing the individualscores on the test. The anchor scores are used only for equating. An equatingplan of this complexity would be impractical for most other tests.
在实际的造作过程中,我们发现ETS非常聪明,如果让同学们在同一时间做两套完整的form来获得算分表非常不现实,因为这会让考试时间double。
所以每一位同学都会公平地分配一个additional section的加试,可能是数学、语法、阅读。这相当于把每次考试十几万的考生分成了3组,一组用来获得这套题目数学的算分表,一组获得语法,一组获得阅读。而且因为每次考试数量足够大,还可以用来测试新题目(这是另一个功能,以后我们再详细介绍新题是如何测试出来的)。
通过这种大规模的测试,CB和ETS可以保证每套新题都能相对稳定。
有的同学可能质疑,如果这套form的题目在之前没用过,虽然在实际考试中可获得算分表,CB怎么样来确保整体难度呢?如果这套题目就是整体偏简单,最终算分表不还是会非常严格吗?
别忘了,每次additional section还会进行新题的测试。CB会收集大量新题的表现,并基本测出每道题目的难度。所以在组卷的时候就可以效仿基准试卷,比如中等难度来10道,高难度来5道进行拼盘,就像菜谱一样。
但是在老SAT时代,也曾有过零星几次算分表及其严格的时候。比如,2014年11月的SAT考试,数学算分表就非常严格,感兴趣的读者可以通过链接:https://www.applerouth.com/blog/2014/12/17/the-trouble-with-the-curve/查看外国网站的报道。
总之在这样一套加试体系之下,CB和ETS因为一下两个原因保证算分表有效:
1>所有投入使用的新题都经过大数据测试,每道题目的难度都有详细的数据支撑,便于组卷的人员拿捏尺寸。
2>整套新卷都可以在第一次考试时通过externalanchor test的设计,得到具有公信力的算分表。
新SAT的算分表呢?一个谜
这种anchor design的设计其实在ETS的各种出品考试中都可见一斑,在TOEFL/GRE考试中考生都须参加additional section的测试。我们能看到,加试在equating和pretesting中产生了很重要的作用。但是自新SAT以来,additional test变得诡异起来。
首先,只有考不带Essay的学生会遇到additional section。在SAT官方发布的advising and admission handbook中,有这样一段话描述加试。
Great care goes into developing and evaluating everyquestion that appears on the SAT. College Board test development committees,made up of experienced educators and subject-matter experts, advise on the testspecifications and the types of questions that are asked. Before appearing in atest form that will count toward a student’s score, every potential SATquestion is:
» Reviewed by external subject-matter experts, such asmath or English educators, to make sure it reflects the knowledge and skillsthat are part of a rigorous high school curriculum. » Subjected to anindependent fairness review process.
» Pretested on a diverse sample ofstudents under live testing conditions for analysis by subgroups. The SAT givenin a standard testing room (to students with no testing accommodations)consists of four components — five if the optional 50-minute Essay is taken —with each component timed separately. The timed portion of the SAT with Essay(excluding breaks) is three hours and 50 minutes. To allow for pretesting, somestudents taking the SAT with no Essay will take a fifth, 20-minute section. Anysection of the SAT may contain both operational and pretest items.
这产生了两个问题。首先,测试范围大幅缩小。在老SAT中,所有的考生都会被加试测试,而在新SAT考生中,根据2018年最新福啊不得数据,仅有32%的考生不选作文,即被加试的学生数量仅有整体考生的32%。再考虑到国际考生几乎从来没有被加试,所以实际加试的学生人数会更少。
其次,如果我们用不考作文的考生进行测试,可能无法代替整体考生。根据官方公布的数字,2018年全年SAT平均分是1068,而考Essay的学生分数是1096分。由此可以推算出,不考essay的学生平均分是1008.5分。可以看出,考essay同学素质要比非essay同学整体素质偏高。这就是所谓的样本偏差的来源。

第三,缺失整套题目的算分表转换方案。在老SAT中,考生会被随机分配一个和正式算分的阅读、语法、数学中某一个section完全一模一样的section作为加试,时间长度、题目结构都完全一致。而新SAT的加试仅有20分钟,比阅读、语法、数学的时间长度都短,且考生知道那个部分是加试。
更重要的是,新题测试的数据可能不准,给未来组卷带来压力。做加试最重要的是学生不知道哪个部分是加试。比如在托福的阅读和听力中,学生不知道哪篇文章、那个section是加试,这就会让学生非常认真地对待每一道题目。
但在新SAT考试中,虽然官方声称任何section都可能含有算分的题目(operational items)和加试题目(pretest items),但从实际操作来看,加试的题目几乎都在第五个section。笔者还没有遇到考试学生汇报带essay和不带essay的前4个section有不一样的情况。
而在老SAT考试中,考生在考试中是无法知道哪个section是加试的,因为加试的section和正式考试的section结构完全一样。只有出了考场同学们相互沟通,才会知道有哪个section不是所有人都遇到的。
所以,在这样的环境下,学生对于additional section的态度大不如以前认真,因为他们有充足的理由相信这部分不会算分。因此测试的结果也不会准确。
综上所述,利用additional section来进行新题的算分表的制作并不具有信服力。同时因为加试学生不认真对待,对于考试前选择试题难易程度组卷也没有特别充分的数据支撑。如果新SAT仍然沿用旧SAT的方式,采用这种externalanchor的方式计算equating,或许能部分解释为什么现在的算分表很不稳定。
有没有可能新SAT在一套form真正投入使用前就已经确定了算分表了呢?笔者对于这样的想法也持怀疑态度。如果在考试前就确定算分表,ETS大概率不会允许这种和OG相差较大的算分表。而且考前通过招募大量考生确定算分表,劳民伤财而且还容易导致题目泄漏。所以算分表大概率是在第一次投入使用时,结合考后学生数据确定的。
还有更糟糕的一点是,有些题目第一次考试时,参考人数可能较少。在人数较少时使用并确定算分表可能导致算分表“畸形”。而这套题目之后再大规模使用,就可能会带来灾难。
比如,2018年6月份使用的多套题目,一些都在下半年进行了复用。比如2018年12月的亚太和北美都重复了6月份的某套题目,而且这套题目并不是6月份主流的那套题目。但是我们充分理解CB的用意,试想,在北美3,5,10月这三场考试,考后都需要公开题目的,因此全美必须使用统一的一套卷子。
所以能用多套题目进行测试的月份只有6,8,11,12和school day test的几个月份。至于今年为什么只在6月份使用了多套题目,还没有想到合理的理由。有可能是试题开发速度不够快。但单从这几个月的考量来看,笔者猜测6月应该是整体相对较少的,因此在6月测试多套题目显得格外的不明智。
目前没有任何公开材料表明新SAT的equating是采用何种技术,以及新SAT如何保证新题测试的准确性。如果读者发现了相关资料,希望能够和我分享,这也是我的困惑之一。
2018年12月亚太算分表也很惨

(国外某网站对于2018年12月亚太卷使用过往试卷的分析,线索为在这三次考试结束后,学生们都在论坛里提到了一篇关于coffeebean的文章)
目前,根据各种信息我们已经确定2018年12月份的SAT亚太考试重复了2018年6月份北美非主流的一套题目,和2018年10月份school day test的题目,也就是说这套题目在今年一年重复使用了3次。
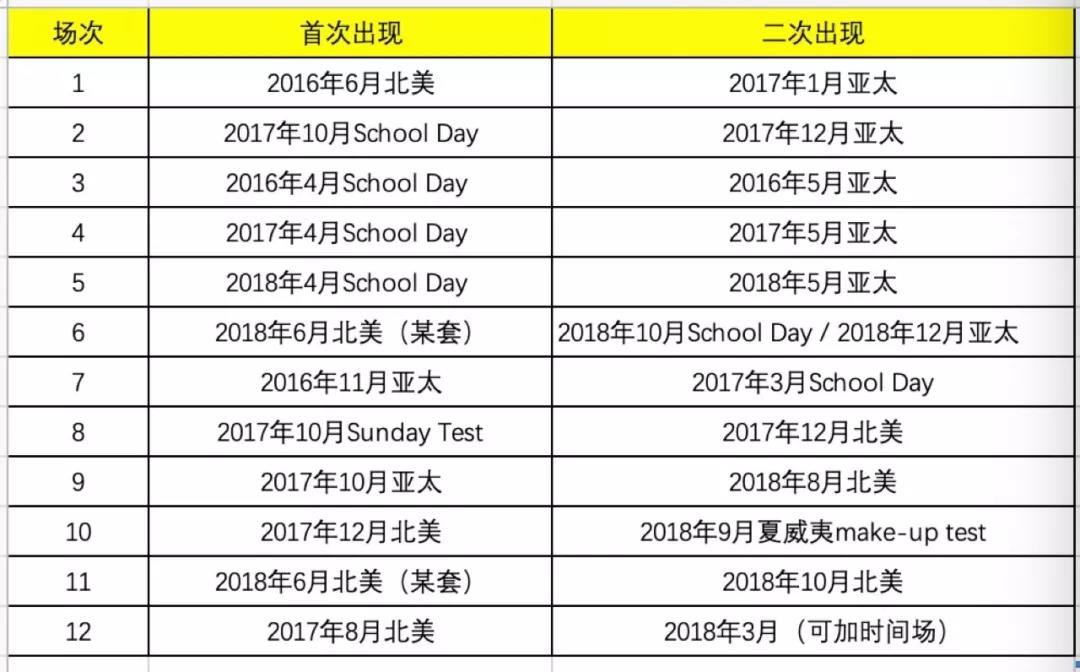
(近几年SAT考试题目可能重复的统计,以上可以看出大致的重复规律:①4月的school day test都在5月的国际考场出现。②上半年6月的多套题目会在下半年开始浮现)
面对不稳定的curve,珍惜每一次考试机会才是最重要的,下一次3月份的考试对于高二学生至关重要,无论curve正常与不正常,每考一次就少一次,所以这个寒假必须全力以赴,争取SAT出分。
最新热文推荐:
(责任编辑:Hui)
